Leveraging Dask for timeseries sampling¶
When loading timeseries selections that would be too large to fit in memory, or to speed up timeseries slicing, you can leverage dask to return lazy arrays to napari to point to yt datasets of a timeseries. The two relevant parameters to yt_napari.timeseries.add_to_viewer() are use_dask and return_delayed.
But first, we’ll spin up a dask client.
As a side note – yt is generally not guaranteed to be threadsafe. But in practice, the sampling in yt_napari does tend to be thread safe as long as you disable yt’s logging, which timeseries.add_to_viewer does internally.
With that said, we’ll spin up a dask client with 5 workers and 5 threads per worker:
[2]:
from dask.distributed import Client
[4]:
c = Client(n_workers=5, threads_per_worker=5)
[5]:
c
[5]:
Client
Client-2d8dc34d-387b-11ee-9086-9d370e7ce927
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: http://127.0.0.1:8787/status |
Cluster Info
LocalCluster
c1666a68
| Dashboard: http://127.0.0.1:8787/status | Workers: 5 |
| Total threads: 25 | Total memory: 31.18 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-5a7d3503-49f5-4332-82e8-b154d3eafca2
| Comm: tcp://127.0.0.1:35003 | Workers: 5 |
| Dashboard: http://127.0.0.1:8787/status | Total threads: 25 |
| Started: Just now | Total memory: 31.18 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:35913 | Total threads: 5 |
| Dashboard: http://127.0.0.1:35249/status | Memory: 6.24 GiB |
| Nanny: tcp://127.0.0.1:33663 | |
| Local directory: /tmp/dask-scratch-space/worker-7h4d23b0 | |
Worker: 1
| Comm: tcp://127.0.0.1:33403 | Total threads: 5 |
| Dashboard: http://127.0.0.1:45843/status | Memory: 6.24 GiB |
| Nanny: tcp://127.0.0.1:40573 | |
| Local directory: /tmp/dask-scratch-space/worker-m13_1ufj | |
Worker: 2
| Comm: tcp://127.0.0.1:38589 | Total threads: 5 |
| Dashboard: http://127.0.0.1:44207/status | Memory: 6.24 GiB |
| Nanny: tcp://127.0.0.1:35659 | |
| Local directory: /tmp/dask-scratch-space/worker-01k1x21b | |
Worker: 3
| Comm: tcp://127.0.0.1:46161 | Total threads: 5 |
| Dashboard: http://127.0.0.1:35787/status | Memory: 6.24 GiB |
| Nanny: tcp://127.0.0.1:34299 | |
| Local directory: /tmp/dask-scratch-space/worker-mb2cnhta | |
Worker: 4
| Comm: tcp://127.0.0.1:39687 | Total threads: 5 |
| Dashboard: http://127.0.0.1:42663/status | Memory: 6.24 GiB |
| Nanny: tcp://127.0.0.1:43027 | |
| Local directory: /tmp/dask-scratch-space/worker-vtv_1v28 | |
and let’s import our packages and initialize a napari viewer:
[6]:
import napari
from yt_napari import timeseries
v = napari.Viewer()
Delayed image stacks¶
When supplying use_dask, it is recommended that you also use load_as_stack, which results in a napari image layer where only the active slice is loaded in memory. Note that it’s good to provide the contrast_limits here as well so that the image is normalized across timesteps.
For 2D slices:
[11]:
%%capture
slc = timeseries.Slice(("enzo", "Density"), "x", resolution=(800, 800))
file_pattern = "enzo_tiny_cosmology/DD????/DD????"
timeseries.add_to_viewer(v, slc, file_pattern=file_pattern, load_as_stack=True,
use_dask=True,
contrast_limits=(-1, 2),
colormap = 'magma',
name="Lazy density")
Parsing Hierarchy : 100%|██████████| 2/2 [00:00<00:00, 17119.61it/s]
Parsing Hierarchy : 100%|██████████| 120/120 [00:00<00:00, 17126.02it/s]
[12]:
from napari.utils import nbscreenshot
nbscreenshot(v)
[12]:

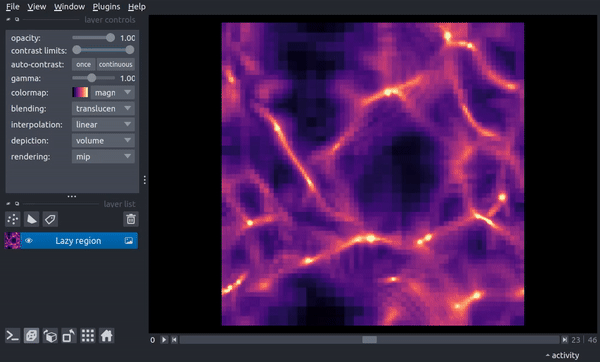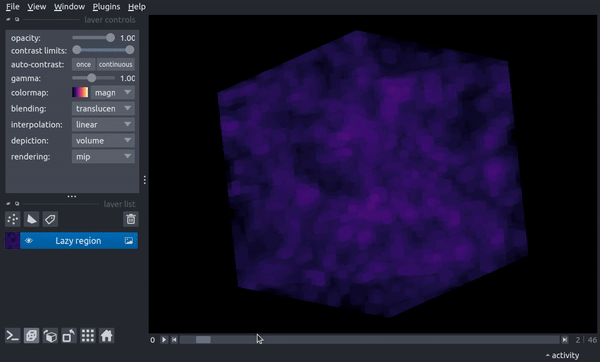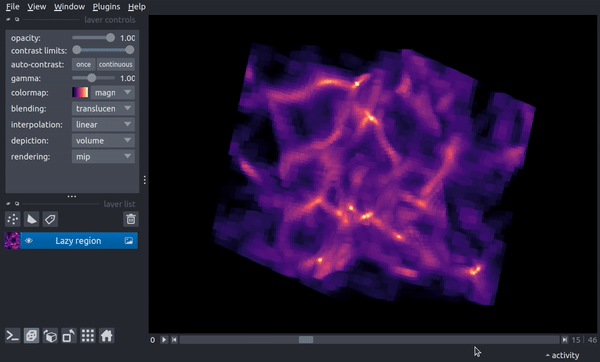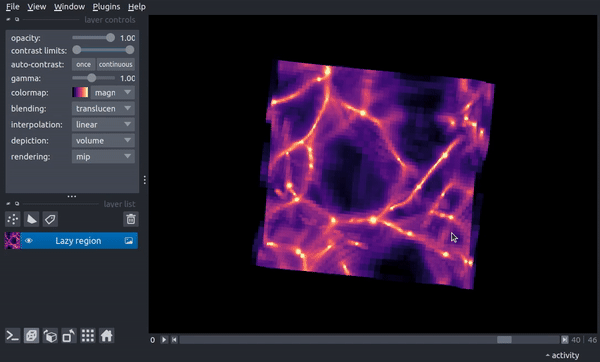
Now, as you drag the slider through, each timestep will be loaded on demand. While this adds a few seconds of processing time, it does allow you to load data that would not fit fully into memory. While less of a problem for slices, the following demonstrates a case that would result in an array roughly 22 Gb in size when loaded in memory:
[19]:
%%capture
reg = timeseries.Region(("enzo", "Density"), resolution=(400, 400, 400))
v.layers.clear()
timeseries.add_to_viewer(v, reg, file_pattern=file_pattern, load_as_stack=True,
use_dask=True,
contrast_limits=(-1, 2),
colormap='magma',
name='Lazy region',)
v.dims.ndisplay = 3
Parsing Hierarchy : 100%|██████████| 2/2 [00:00<00:00, 16912.52it/s]
Parsing Hierarchy : 100%|██████████| 2/2 [00:00<00:00, 16131.94it/s]
Parsing Hierarchy : 100%|██████████| 120/120 [00:00<00:00, 4619.24it/s]
Parsing Hierarchy : 100%|██████████| 2/2 [00:00<00:00, 17623.13it/s]
Parsing Hierarchy : 100%|██████████| 41/41 [00:00<00:00, 1803.40it/s]
Parsing Hierarchy : 100%|██████████| 86/86 [00:00<00:00, 2899.93it/s]
Parsing Hierarchy : 100%|██████████| 189/189 [00:00<00:00, 6309.63it/s]
Parsing Hierarchy : 100%|██████████| 187/187 [00:00<00:00, 6255.16it/s]
Parsing Hierarchy : 100%|██████████| 194/194 [00:00<00:00, 6509.09it/s]
Parsing Hierarchy : 100%|██████████| 214/214 [00:00<00:00, 6973.94it/s]
and now clicking through timesteps loads a new 3D region on demand:
Using dask, returning in-memory image array¶
Finally, for the case where you can fit the whole image array in memory, you can set returned_delayed to False and dask will be used to fetch the selections. This works best for slices, where you probably can safely fit all those slices in memory.
[21]:
%%time
slice = timeseries.Slice(("enzo", "Density"), "x", resolution=(1600, 1600))
v.layers.clear()
v.dims.ndisplay = 2
timeseries.add_to_viewer(v, slice, file_pattern=file_pattern, load_as_stack=True,
use_dask=True,
return_delayed = False,
contrast_limits=(-1, 2),
colormap='magma',
name='Density stack')
Parsing Hierarchy : 100%|██████████| 2/2 [00:00<00:00, 15279.80it/s]
Parsing Hierarchy : 100%|██████████| 120/120 [00:00<00:00, 4467.13it/s]
Parsing Hierarchy : 0%| | 0/143 [00:00<?, ?it/s]
Parsing Hierarchy : 100%|██████████| 104/104 [00:00<00:00, 16175.61it/s]
Parsing Hierarchy : 100%|██████████| 143/143 [00:00<00:00, 8985.15it/s]
Parsing Hierarchy : 100%|██████████| 76/76 [00:00<00:00, 3526.97it/s]
Parsing Hierarchy : 100%|██████████| 2/2 [00:00<00:00, 16256.99it/s]
Parsing Hierarchy : 100%|██████████| 66/66 [00:00<00:00, 13773.71it/s]
Parsing Hierarchy : 100%|██████████| 2/2 [00:00<00:00, 5349.88it/s]
Parsing Hierarchy : 100%|██████████| 55/55 [00:00<00:00, 14746.02it/s]
Parsing Hierarchy : 100%|██████████| 3/3 [00:00<00:00, 17452.03it/s]
Parsing Hierarchy : 100%|██████████| 66/66 [00:00<00:00, 17745.13it/s]]
Parsing Hierarchy : 100%|██████████| 94/94 [00:00<00:00, 17771.67it/s]
Parsing Hierarchy : 100%|██████████| 139/139 [00:00<00:00, 2523.78it/s]
Parsing Hierarchy : 0%| | 0/54 [00:00<?, ?it/s]]
Parsing Hierarchy : 100%|██████████| 54/54 [00:00<00:00, 18747.82it/s]
Parsing Hierarchy : 100%|██████████| 111/111 [00:00<00:00, 10577.48it/s]
Parsing Hierarchy : 0%| | 0/143 [00:00<?, ?it/s]4590.70it/s]
Parsing Hierarchy : 100%|██████████| 114/114 [00:00<00:00, 18968.96it/s]
Parsing Hierarchy : 100%|██████████| 99/99 [00:00<00:00, 6648.88it/s]
Parsing Hierarchy : 100%|██████████| 143/143 [00:00<00:00, 11197.97it/s]
Parsing Hierarchy : 100%|██████████| 132/132 [00:00<00:00, 5547.08it/s]
Parsing Hierarchy : 100%|██████████| 86/86 [00:00<00:00, 17127.74it/s]
Parsing Hierarchy : 0%| | 0/132 [00:00<?, ?it/s]9903.35it/s]
Parsing Hierarchy : 100%|██████████| 137/137 [00:00<00:00, 9233.21it/s]
Parsing Hierarchy : 100%|██████████| 132/132 [00:00<00:00, 531.11it/s]
Parsing Hierarchy : 100%|██████████| 159/159 [00:00<00:00, 2609.95it/s]
Parsing Hierarchy : 100%|██████████| 162/162 [00:00<00:00, 3238.72it/s]
Parsing Hierarchy : 100%|██████████| 189/189 [00:00<00:00, 3253.72it/s]
Parsing Hierarchy : 100%|██████████| 189/189 [00:00<00:00, 1502.02it/s]
Parsing Hierarchy : 100%|██████████| 160/160 [00:00<00:00, 2137.21it/s]
Parsing Hierarchy : 0%| | 0/201 [00:00<?, ?it/s]
Parsing Hierarchy : 100%|██████████| 12/12 [00:00<00:00, 16100.98it/s]
Parsing Hierarchy : 100%|██████████| 201/201 [00:00<00:00, 9435.63it/s]
Parsing Hierarchy : 100%|██████████| 194/194 [00:00<00:00, 8609.80it/s]
Parsing Hierarchy : 0%| | 0/146 [00:00<?, ?it/s]
Parsing Hierarchy : 100%|██████████| 146/146 [00:00<00:00, 9293.52it/s]
Parsing Hierarchy : 100%|██████████| 167/167 [00:00<00:00, 6510.17it/s]
Parsing Hierarchy : 100%|██████████| 182/182 [00:00<00:00, 2992.56it/s]
Parsing Hierarchy : 100%|██████████| 38/38 [00:00<00:00, 1830.10it/s]
Parsing Hierarchy : 100%|██████████| 187/187 [00:00<00:00, 2728.71it/s]
Parsing Hierarchy : 100%|██████████| 146/146 [00:00<00:00, 5163.48it/s]
Parsing Hierarchy : 100%|██████████| 196/196 [00:00<00:00, 3391.56it/s]
Parsing Hierarchy : 100%|██████████| 33/33 [00:00<00:00, 9558.84it/s]
Parsing Hierarchy : 100%|██████████| 41/41 [00:00<00:00, 7446.69it/s]
Parsing Hierarchy : 100%|██████████| 21/21 [00:00<00:00, 18594.13it/s]
Parsing Hierarchy : 100%|██████████| 211/211 [00:00<00:00, 10013.78it/s]
Parsing Hierarchy : 100%|██████████| 24/24 [00:00<00:00, 19421.82it/s]
Parsing Hierarchy : 100%|██████████| 188/188 [00:00<00:00, 4992.37it/s]
CPU times: user 1.11 s, sys: 800 ms, total: 1.91 s
Wall time: 12.1 s
and we’ve taken our ~30s selection time down to ~12s.
[22]:
c.close()
[ ]: